I've been working on my lot of machine learning stuff lately. It started from learning NLP now it has come to quantizing and deploying. I have not deployed any model yet but in an attempt to do so I did learn about Quantization.
So what is this quantization? How is it useful? Why is it useful? you will get to know. So you can imagine quantization as putting a model in diet. We are making a model consume less food. We reduce the model's precision from a long floating point number to an integer. But if you're here for formal definition here it is:
Quantization is a technique to reduce the computational and
memory costs of running inference by representing the
weights and activations with low-precision data types like
8-bit integer (int8) instead of the usual 32-bit floating
point (float32).
Somehow I have made my analogy feel worse than the actual definition. Concerning. Anyways back to the topic. Picture yourself as someone hyped about AI models. Then a company, famously “open” but actually kinda “closed”, drops a shiny new open source model (finally living upto it's name). You’re one of those people who swear “AI will replace us,” whatever that means. You want to try out that free and open-source model. ***Problem: it’s massive ***(that's what she said). Even your GPU-less laptop starts crying just looking at it. This is where quantization enters the chat. It is the trick that turns a mamoth of a model into something that actually runs on a potato.
So what does it do? "It just maps the long precision float point numbers into integers".
But how does it make the model leaner? If you know binary (not the sexual or gender thing,
also don't tag them),you must also know the space occupied by the floating point numbers and integers.
A float32 is 32 bits, an int8 is just 8 bits.That’s literally 4x less memory per weight.
And since models are basically millions or billions (now we have trillions) of these numbers, the
savings add up fast. Imagine for a model of 20b parameters. If each parameter is stored as a
float32 (4 bytes) it will take around 80 GB. If we quantize to int8 (1 byte) it takes approximately
20 GB. You get to see like ~75% reduction in size. That is pretty cool right. That is insane.
So I decided to mess around it using some model. I used Qwen/Qwen3-1.7B model and use huggingface with bits and bytes to quantize it. After Quantizing the base model these were the results.
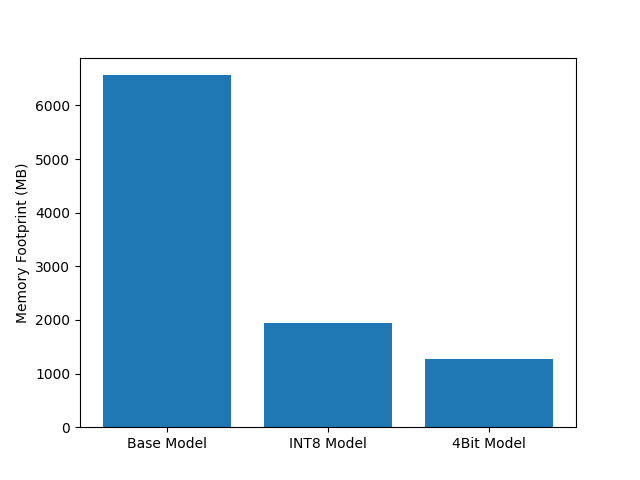
You're looking at the disk space required by each model. The base model uses around 6.5 GB, 8 bit model takes approximately 2 GB and the 4 bit model smallest of all takes around 1.3 GB. We made 6.5 GB model into 1.2 GB model. You might ask me? Wait, won't it affect the quality of answer? It does affect the quality but it depends on factors like the base models size, no of times we've quantized the model and more.
I ran these models on Kaggle using kaggle notebook. I recommend that you guys try kaggle it is much nicer to use and also we have more GPU time than collab's free tier. You get access to GPU for 30 hrs a week. It's an offer I couldn't refuse.So try it out.
Unfortunately my files have been corrupted or I uploaded it in a way that is messed up. I have to find a way to benchmark those models and provide those results soon.
I will upload them soon!!!
If you guys liked it or found it informative or useful. Share it to more people!! Aso like on linkedin.